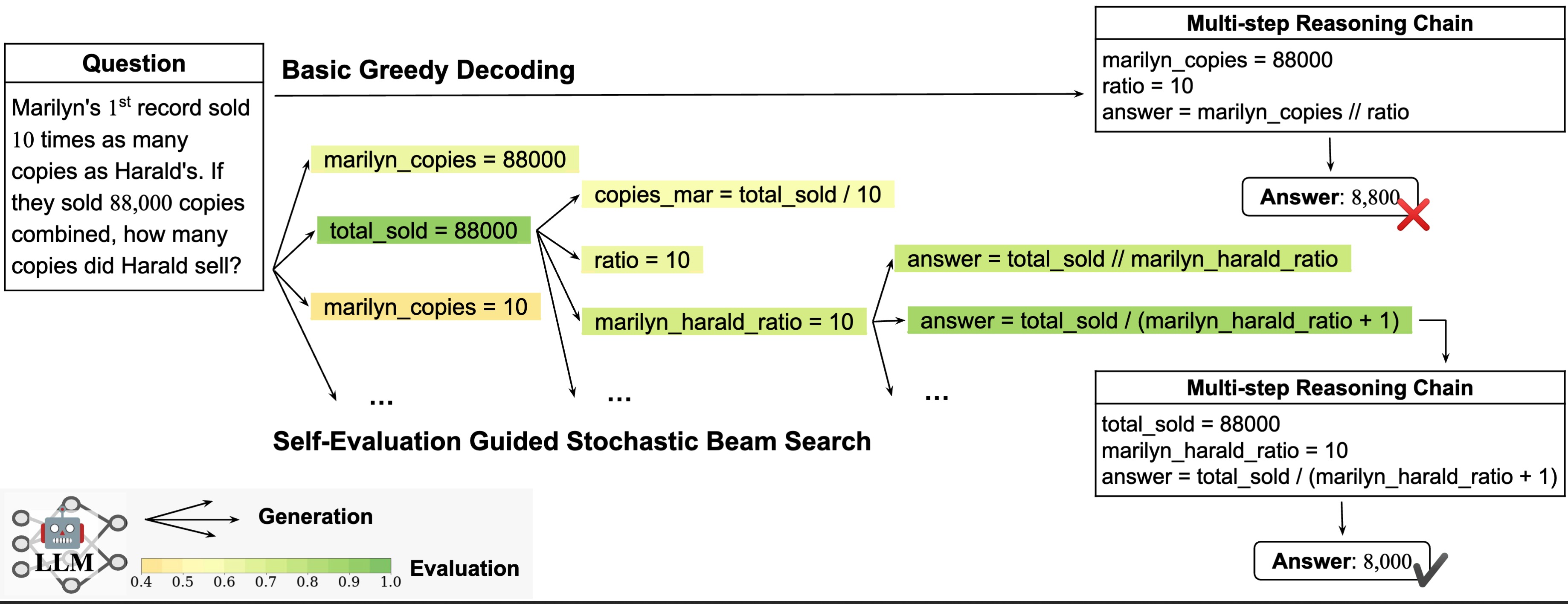
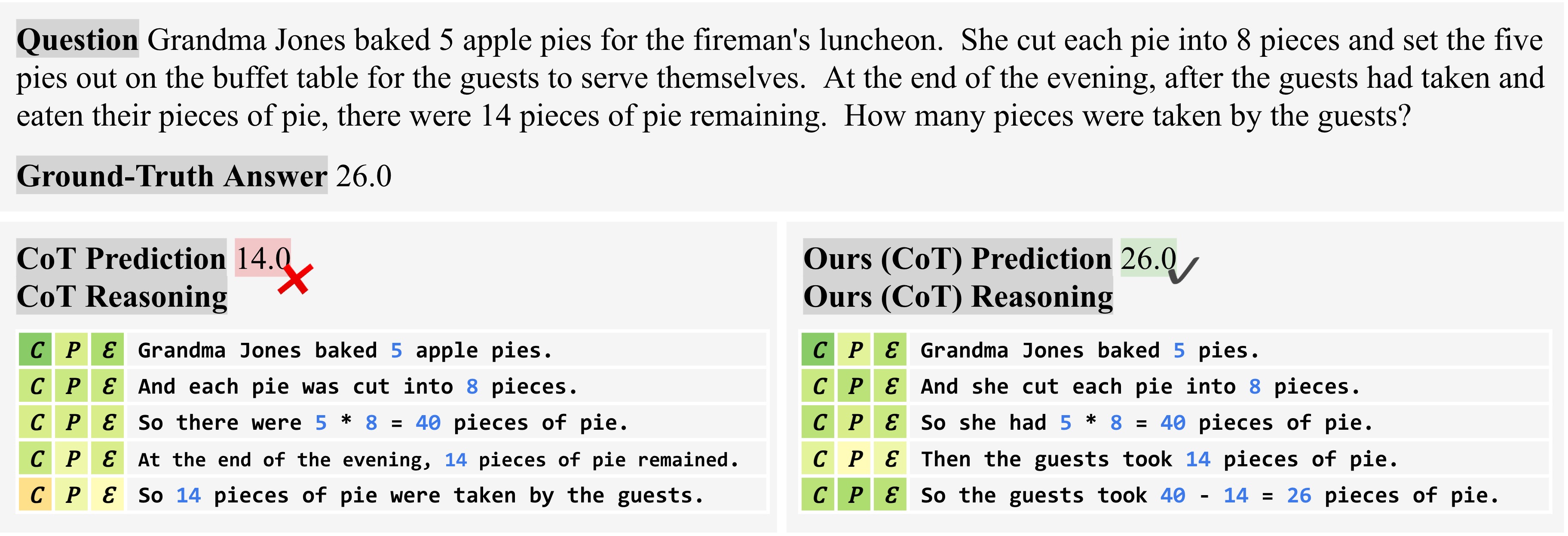
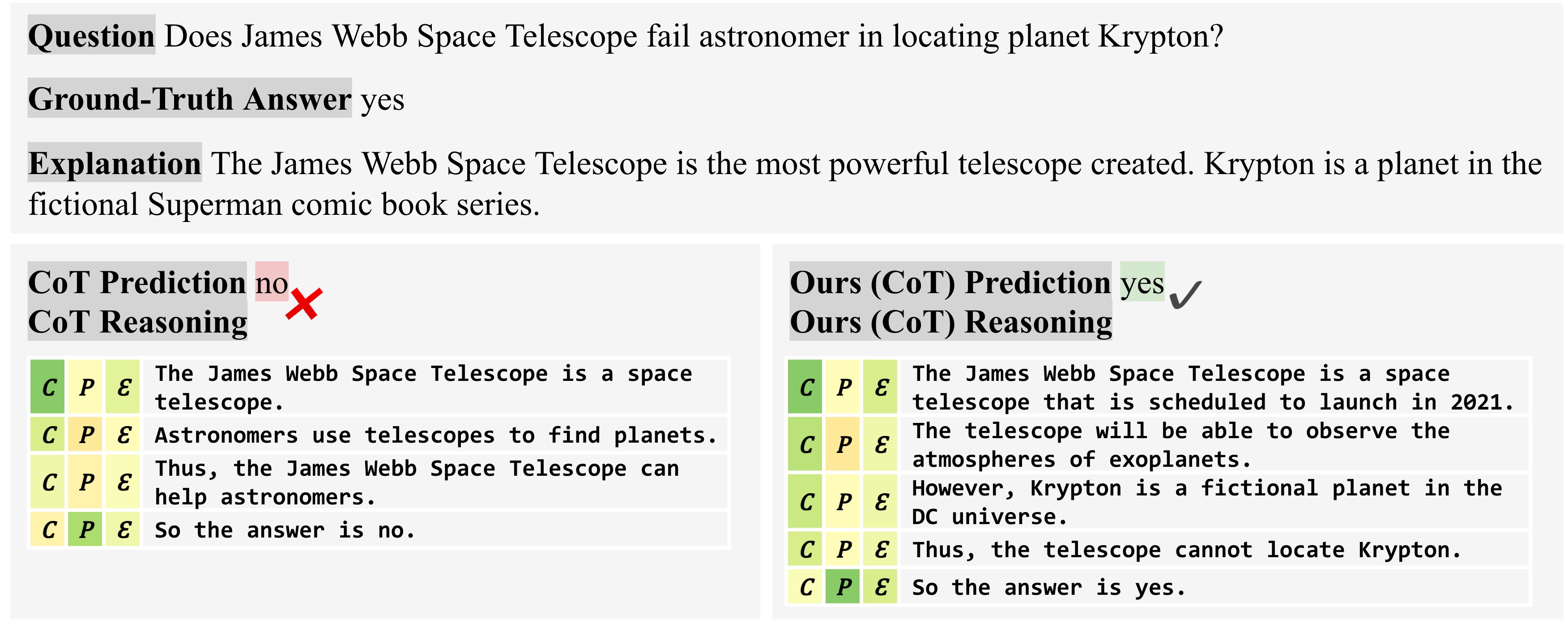
We compare the predictions of baseline and our methods on particular instances.
Scores from low to high are visualized from orange, yellow, to green. Here \(\mathcal{C}\), \(\mathcal{P}\), and \(\mathcal{E}\) represent the evaluation confidence, the generation confidence (probability), and their combination as the final self-evaluation score, respectively.
In general, the evaluation confidence \(\mathcal{C}\) is more effective at identifying logical errors, taking into account accumulated mistakes from prior steps, while the generation probability \(\mathcal{P}\) focuses more on text perplexity as the confidence of the LLM generator.